Mimicking the Pagerank Algorithm
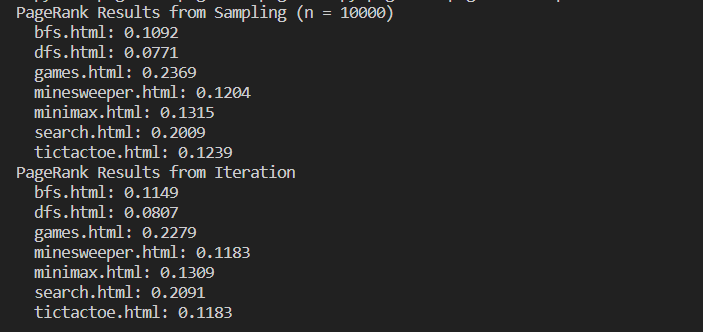
About the project:
This was a project in the cs50ai track that asked me to employ the pagerank algorithm both by iteration and by sampling. It sorts based on the number of pages a certain page is linked to and how many pages it itself links to. It does not count self references and has a bit of randomness when sampling in order to avoid being stuck in a closed loop of links. You can see how sampling and iteration are pretty close, but sampling would be much quicker for larger data sets. You can find the code on GitHub here: https://github.com/c-crowder/cs50_ai/tree/main/pagerank/pagerank
Technology used:
Python